|
|
.NET database and distributed computing tools |
|
|
|
|||||||||
 A
popular notion about databases is that they don't "scale"
well, i.e. that it's too difficult to keep growing the size a
database, or too hard to handle the load of an increasing number of
concurrent users. To put it differently, some believe that
database-centric design is fundamentally incapable of efficiently
meeting the demands of high-performance distributed computing. We
disagree.
A
popular notion about databases is that they don't "scale"
well, i.e. that it's too difficult to keep growing the size a
database, or too hard to handle the load of an increasing number of
concurrent users. To put it differently, some believe that
database-centric design is fundamentally incapable of efficiently
meeting the demands of high-performance distributed computing. We
disagree.The components of a large database
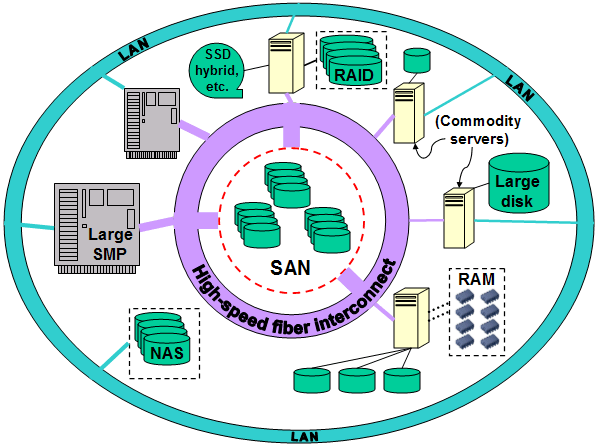
|
In the olden days, someone came up with the bright idea of using a little
disk icon to symbolize an entire database. This is a convenient
abstraction, but one also should have some appreciation of what that little
"database" icon really represents. As you can see in the diagram above, a single database actually may consist of a large number of components, including arrays of disk drives and powerful processors, interconnected by high-speed networks and communications channels. |
Database scalability has come a long way from simply having the option of buying
a bigger hard drive or plugging it into a faster server. Nowadays, DBMS software
can orchestrate a huge configuration of computers, storage devices, and network
infrastructure, to appear as a single logical database - as big and as fast as
you'd ever want. Let's take a closer look at how one goes about increasing database size and performance, and examine what goes into deciding the best way grow a database application. |
Increasing database storage capacity
|
Traditionally, the way to make a database larger has been to buy a bigger hard drive, or add an extra one. This is still one of simplest, most economical solutions, thanks to the dramatic growth in disk capacity and drop in cost per megabyte. At the high end, widely used disk storage technologies include Redundant Arrays of Inexpensive Disks (RAID), Network Attached Storage (NAS), and Storage Area Networks (SAN). These technologies provide greater fault tolerance and enhanced sharing capabilities. |
For the largest databases, SANs offer benefits in cost and performance, as well as centralized administration. Besides improving capacity utilization, SANs support high-speed, remote backup and replication services without burdening the primary network. Today's low cost disks have virtually eliminated practical limits to raw storage capacity, but speed is another matter. Drives are faster than before, but not nearly as much so as they are bigger and cheaper. That brings us to a variety of techniques for improving database performance, starting with better utilization of memory. |
Using memory to make the database faster
| The easiest way to speed up a database server is to give it more memory (RAM). Databases are particularly good at caching, especially with regard to indexes, so the addition of memory can yield a major improvement in overall performance. This simple method of scaling up continues to be highly attractive, because the cost of memory has declined as dramatically as that for disk storage. Also, with the advent of 64-bit computing, there ceases to be a hard limit on the amount of memory that a processor can use. | Adding more memory reduces idle CPU time spent waiting for relatively slow disk drives. Eventually, as the rate of concurrent database activity increases, one reaches a limit imposed by the CPU itself. When this occurs, there's no point to adding more memory, so the next step is to scale up the database server's processing power. |
Scaling up to more powerful CPUs and servers
|
Thanks to a continual stream of major improvements in processor technology, you won't have to wait long for more ways of easily scaling up to a faster server. With the advent of 64-bit CPUs and new multi-processor / multi-core architectures, processor scalability has been greatly extended beyond the dimension of CPU speed. DBMS products were among the first to take advantage of these new technologies, leading to new a generation of much more powerful, commodity servers. |
If a run-of-the-mill server with dual quad-core, 64-bit Xeon CPUs and 32 GB of RAM isn't enough to satisfy your thirst for processing power, you'll be happy to know that you can scale up still further to a large Symmetric Multiprocessing (SMP) server, for example, running under Windows Server 2003 with 64 Xeon 64-bit CPUs sharing 1 Terabyte of main memory. A large SMP machine isn't cheap, but for a database big enough to require such a massive beast, it may be cost-effective. |
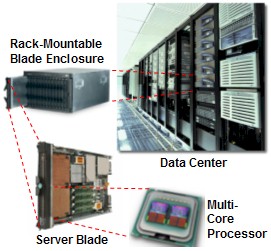
Evolution of the commodity server
|
Twenty years ago, a couple of thousand dollars might buy you a decent server with a 50 MHz processor, a few MB of memory, 100 MB hard drive, and a 10 Mbit/s Ethernet adapter. Today's commodity server, for approximately the same cost, is a "blade" - a stripped-down computer board that slides into an enclosure holding up to a dozen or more blades in the space of yesterday's server box. Yet a single server blade, at less than a tenth the size of its predecessor, packs about a thousand times the processing power, memory, disk capacity, and communications speed. |
|
Scaling out across multiple database servers
| Long before the latest generation of super-charged CPUs, the need to harness more database processing power led to the development of a number of techniques for "scaling out" database servers, i.e. adding loosely-coupled servers, instead of just making them bigger ("scaling up"). These techniques allow greater use of low-cost commodity servers, while providing still higher levels of total database processing power. | To begin with, one can exploit an application's natural lines of division by storing separate tables on different servers (guided by an analysis of usage patterns). Taking things further, DBMS software supports transparent partitioning of large tables across multiple servers, based on ranges of primary keys. Yet another approach, Oracle's Real Application Clusters (RAC), offers a flexible, scalable architecture relying on high speed interconnection of multiple servers, each with access the entire database and a shared database cache. |
High-speed connections between database components
|
Huge advances in high-speed communications, such as Gigabit and 10 GB Ethernet and Fibre Channel technology have contributed greatly to the viability of ever larger, loosely-coupled database server configurations. Network Attached Storage (NAS), for example, can be a very economical way of giving many servers rapid access to a common set of shared database files. Storage Area Networks (SAN) provide the highest level of performance in multi-processor database servers that share a common database. |
By employing a switched "fabric" of Fibre Channel connections, each processor or server can
access the entire shared database through a SAN as if it resided on a directly
attached disk. Another way that communications can improve the performance of large, multi-server databases is by providing high-speed interconnections directly between servers. Effectively, separate machines can share a common pool of memory, for example the database cache (as in Oracle's RAC), which can substantially boost performance. |
Database transaction processing
|
Transaction processing (TP) is an essential, but frequently misunderstood service provided by DBMS software to guarantee database reliability, integrity, and the ability to recover from unpredictable failures. Through various optimizations, TP overhead can be kept at a modest level, enabling databases to sustain much higher transaction rates than one might imagine. A DBMS transaction monitor must have some centralized control data that is rapidly accessible to all of the servers sharing a common database. Fortunately, this highly active central data structure requires only a relatively small amount of temporary storage. Hence the most intensively used TP component is implemented as a fast, memory-resident control structure, which benefits strongly from shared memory and high-speed direct connections between servers. TP mechanisms also use an "undo" log to support ROLLBACK operations for transactions while they are in progress. Since this data is short-lived and does not require synchronous disk I/O, conventional buffering and caching suffice to assure that writing to the undo log doesn't impose a substantial delay. |
On the other hand, careful synchronization is necessary in the generation of "redo" logs, critical for recovery from crashes. These logs call for a highly reliable form of persistent storage, such as RAID disks. When a transaction is committed, the redo information must have been written. However, this does not imply that each transaction incurs a blocking disk I/O operation, because the redo information for many independent transactions can be buffered into a single physical output to the log. Substantial further speedups to the redo log can be had through battery-backed caching controllers, hybrid disks, and Solid State Disk (SSD), as well as virtual shared memory in clustered server configurations. Thus, contrary to popular belief, the overhead of TP log output to "stable storage" can be reduced to a much smaller expense than that of a normal disk I/O to the database. Another common misconception is that distributed processing of transactions requires the XA architecture of "distributed transactions", which adds a potentially costly, extra layer of global transaction monitoring. In reality, such models of distributed transactions are seldom optimal. Efficient alternative techniques, like multi-step asynchronous jobs and compensating transactions, are generally more suitable for coordinating loosely coupled, independent databases. |
Optimizing database design and configuration
|
Despite spectacular advances in database hardware and software technology, successful implementation of a large database depends most of all upon the skill of application developers. Neither expensive equipment nor high-end DBMS software can adequately compensate for a fundamentally flawed design. On the other hand, a sound, well executed design frequently produces good results even without resorting to the most costly components and tools. To achieve the most economical solution, it's important to recognize the different categories of database storage and their processing requirements, so these can be well matched to the most appropriate technology. Beyond pure price / performance, database designers also need to consider reliability and recoverability, security, and maintainability, plus additional performance parameters, such as peak capacity, average response time, power consumption, etc. While the tools and techniques are general, good solutions must be designed around the particular requirements of each database application. For example, it makes a big difference whether part of the data is fairly static, as opposed to being subjected to frequent updates. |
Depending on size and frequency of use,
static data could be stored on lower cost shared storage media (e.g. NAS),
or a subset might be replicated through transparent DBMS services, for
better performance. Temporary storage, on the other hand, while crucial to DBMS
performance, does not need to be shared, and would typically be best
situated on a directly attached disk drive. One of the most critical aspects of database design is the proper utilization of indexes, which can vastly increase the system's speed while reducing disk I/O and processing. Typically the indexes comprise a small portion of the entire database, but they demand a relatively high grade of fast, shared storage, compared to the bulk of the data. Indexes benefit strongly from caching, so it's best to supply an ample amount of RAM for this purpose. Another special category of storage is that which is used internally by the DBMS for transaction processing, including logs needed for recovery from failures. Transaction-intensive databases can benefit greatly by using a modest amount of very fast, reliable storage for these logs, through such technologies as SSD, hybrid drives, and various distributed memory schemes. |
Summary and Conclusions
|
Building extremely large database applications can be very challenging, but people have been doing it successfully for quite a while, and there is every reason to expect that database technologies will keep getting better. In fact, mass storage, processors, and communications have already evolved to the point where few applications are beyond the reach of a modest investment in commodity components, and it would be difficult to imagine any realistic application whose requirements exceed the capabilities of the largest possible configuration of today's hardware and DBMS software. |
On the other hand, as databases grow larger and systems become more complex, the job of the application designer becomes more difficult, and we are not so confident that people will be getting much smarter, real soon. So the practical limits of database scalability really are no longer dictated by hardware, but by software. Fortunately, relational databases have been very successful at simplifying the job of application developers, freeing them from a vast amount of underlying complexity. DBMS technology continues to improve, with no end in sight, but it remains for application developers to be ever vigilant against the intrusions of needless complexity. |
Visual Studio .NET | B1Framework | Efficient Multiprocessing | Database Scalability
|
|
|||||||
| Home | Products | Consulting | Case Studies | Order | Contents | Contact | About Us |
|
|
|||||||
|
Copyright © 2012, Base One International Corporation |
|||||||